






Reltio AgentFlow is opening the door to a new class of “hands-off” data operations, where AI agents take care of routine stewardship tasks with minimal human intervention. One of the highest‑value use cases is automating updates to Reference Data Management (RDM) using simple file uploads—no complex mappings, no ETL, and no custom UI work. In this blog, we’ll walk through how to design and build an agent that can update RDM using direct CSV uploads and intelligent processing.
Why an Agent for RDM Updates?
RDM sits at the heart of any serious MDM landscape: countries, industries, product hierarchies, customer segments, codes, and value lists that every application depends on being consistent and controlled. Traditionally, updating that reference data means:
- Manually transforming spreadsheets into RDM‑friendly formats
- Managing brittle mapping specs between columns and RDM attributes
- Coordinating with IT or data engineering for every change
This is exactly the pattern AgentFlow is designed to eliminate. Instead of asking users to learn RDM schemas or mapping tools, you give them a simple workflow:
- Upload a CSV or structured text file.
- Let the agent understand the structure and infer mappings.
- Have the agent call RDM APIs to apply updates safely.
The key is designing an agent that feels like a “smart assistant for reference data” rather than just an API wrapper.
Target Experience: What the Agent Should Do
Before we get into implementation, define the end‑user experience you want inside Reltio:
- Users can upload a CSV file directly in the AgentFlow workspace.
- They describe what they want:
“Update the Country lookup with these new ISO codes and descriptions.” - The agent inspects the file, decides which columns map to which RDM fields, and validates basic quality.
- It generates the correct RDM payload and calls the RDM APIs to insert or update values.
- It returns a friendly summary: what changed, what failed, and what the user might need to fix.
The four design pillars that enable this are:
- Direct file upload
- Intelligent processing
- No explicit mapping configuration
- Multi‑format support
Let’s unpack each and translate them into architecture and implementation.
Architectural Overview
At a high level, your solution involves four components:
- AgentFlow agent: The orchestrator that interprets user intent and drives the workflow.
- AI reasoning layer: Handles column/field understanding, format recognition, and mapping inference.
- File ingestion & parsing: Accepts CSV or text and converts it into a structured internal representation.
- RDM update layer: Encapsulates calls to Reltio RDM APIs (create/update lookups, values, attributes).
A typical interaction looks like this:
- User uploads file + instruction.
- Agent retrieves and parses the file.
- AI infers schema and mapping (“Code” →
code, “Description” →name, etc.). - Agent generates RDM payload (upserts, partial updates).
- Agent calls RDM APIs and captures responses.
- Agent summarizes outcome and, if needed, recommends another iteration or correction.
Think of AgentFlow as the conductor, the AI model as the analyst, and the RDM APIs as the execution engine.
Step 1: Define the RDM Update Use Cases
Start with concrete RDM scenarios instead of trying to build a universal agent from day one. Common use cases:
- Value list creation and updates
- Country codes, currencies, languages, units of measure.
- Domain‑specific lookups
- Industry classification, product categories, risk tiers, loyalty tiers.
- Crosswalk tables
- Source code to canonical code mappings, legacy to new system codes.
For each use case, define:
- The RDM lookup type (e.g.,
Country,Industry,ProductCategory). - The minimal set of fields you expect (code, name, status, effective date, etc.).
- How you want to treat data: “upsert” semantics (update existing code, create if new) vs “insert only.”
This will inform your validation logic and the prompts you craft for the AI model.
Step 2: Enable Direct File Upload
The user should not need any preprocessing; “drop the CSV and go” is the goal.
Key design points:
- Accept CSV as the primary format but be lenient with delimiters (comma, semicolon, tab).
- Allow structured text as a backup (e.g., pasted tables exported from another system).
- Store the file in a temporary, secure location for the duration of the agent run.
- Enforce size limits and row caps for performance (e.g., 5–10 MB, up to tens of thousands of rows per run).
Implementation‑wise, you’ll usually:
- Add a file input to the AgentFlow task UI (or endpoint if integrating via API).
- Pass the file reference into the agent’s context so it can be retrieved and parsed.
- Route the raw bytes into your parsing layer (e.g., Python, Node.js, or a service).
From the user’s perspective, it should feel similar to uploading a file to a web form, but with an AI assistant behind it.
Step 3: Intelligent Processing – Make the Agent “Understand” the File
This is where the AI earns its keep. We want the agent to:
- Detect file type and delimiter automatically.
- Infer column meanings and map them to RDM attributes.
- Validate and normalize values where possible.
You can use a layered approach:
- Basic parsing layer
- Use a CSV parser to extract header names and rows.
- Sample the first N rows to understand patterns (e.g., numeric codes, text descriptions).
- AI inference layer
- Construct a prompt like:“You are an RDM assistant. Given the header names and data samples, map each column to one of: code, name, description, sourceCode, status, startDate, endDate, parentCode, or ‘ignore’ if not relevant.”
- Provide a small JSON schema as the output format.
- Optionally, include hints about the target lookup type (country vs industry, etc.).
- Validation layer
- Check that mandatory fields are present (e.g., code and name).
- Flag suspicious columns (e.g., multiple candidates for “description”).
- Optionally, involve the user if ambiguity is high (“I found two possible ‘description’ columns…”).
The objective is a clean, explicit mapping structure like:
json{
"lookupType": "Country",
"columns": {
"Code": "code",
"Country Name": "name",
"ISO2": "sourceCode",
"Status": "status"
}
}
You can then apply this mapping mechanically across all rows.
Step 4: Remove Manual Mapping – No Config Screens
Traditional data onboarding requires users to click through mapping screens to link columns to target fields. In your agent:
- The AI decides the mapping.
- The mapping is documented in the agent’s reasoning output.
- The user only steps in when something is unclear (e.g., optional confirmation step for high‑risk domains).
Design choices to support the “no mapping required” promise:
- Use consistent header naming conventions across your templates and training.
- Maintain a small internal dictionary of “synonyms” (e.g.,
Code,CD,Value,Key→code). - Let the AI see past successful mappings as examples to improve its next guess.
An additional enhancement is to store the inferred mapping with the file or lookup type, so that future uploads with similar headers use the same mapping automatically.
Step 5: Support Multiple Input Formats
While CSV is the natural hero, real life brings variety. You can increase adoption by supporting:
- Standard CSV (commas, UTF‑8).
- Semicolon or tab‑delimited files from legacy tools.
- “Structured text” pasted into a textbox (pipe‑separated, Markdown‑like tables, etc.).
A simple strategy:
- Try CSV parsing with multiple delimiters; if parsing fails or results in a single huge column, fall back.
- For structured text, split on newlines, then split each line by the most frequent delimiter character.
- Always standardize into an internal tabular format: headers + rows array.
For the agent, “multiple formats” is invisible; it always operates on a unified tabular representation.
Step 6: Generate RDM Payloads
Once the agent understands the file and has a mapping, it must convert rows into valid RDM API payloads. At a conceptual level:
- Each row becomes a candidate reference value.
- Existing codes should be updated; new codes should be created (upsert).
- Optional: deactivation logic if a code disappears from the latest file.
A typical per‑row structure might look like:
json{
"code": "US",
"name": "United States",
"attributes": {
"iso2": "US",
"status": "ACTIVE"
}
}
Batching is important:
- Chunk rows into batches (e.g., 500–1000 rows) to avoid oversized requests.
- Implement basic retry logic for transient failures.
- Capture per‑row success/failure for reporting back to the user.
At this point, the agent is just performing deterministic transformations and API calls—the “smart” part is behind it.
Step 7: Call the RDM APIs from the Agent
Your agent needs a small RDM integration layer that:
- Authenticates against Reltio (e.g., client credentials).
- Exposes simple functions the agent can call, such as:
getLookupValues(lookupType, codes)upsertLookupValues(lookupType, values[])deactivateMissingValues(lookupType, fileCodes)(optional)
Within the agent’s orchestration logic:
- Fetch existing values so you can distinguish between updates and inserts.
- Build upsert lists per batch.
- Send the batch, log responses, and accumulate statistics.
From the agent’s perspective, this can be described as a set of “tools”:
tool.rdm.previewChanges– show what would change, with a dry‑run flag.tool.rdm.applyChanges– actually perform upserts.tool.rdm.exportLookup– export current values if you want to show a before/after.
This separation lets you offer users both “Preview” and “Apply” flows using the same building blocks.
Step 8: Design the Conversation Flow in AgentFlow
The agent shouldn’t just silently process; it should communicate:
- Initial understanding
- “I’ve detected a CSV file with 3 columns and 500 rows. It looks like Country data. I’m mapping ‘Code’ → code, ‘Country Name’ → name, ‘ISO2’ → sourceCode.”
- Optional confirmation
- For high‑risk domains:
“Do you want to review and confirm this mapping, or should I proceed?”
- For high‑risk domains:
- Preview of impact
- “I found 450 existing codes that will be updated and 50 new codes that will be created. No values will be deactivated.”
- Execution
- “Applying batch 1 of 5 (100 rows)... done.”
- Final summary
- “Updated: 450. Created: 50. Failed: 0. You can export the updated lookup for verification.”
This conversational structure builds user trust and makes the agent feel like a collaborator rather than a black box.
Step 9: Handle Edge Cases and Governance
Production RDM changes carry risk. Your agent should be opinionated about guardrails:
- Validation rules
- Reject rows with missing mandatory fields.
- Flag duplicate codes in the same upload.
- Perform basic referential checks (e.g., parent codes exist).
- Environment handling
- Run first in a lower environment (dev/QA) and promote patterns to prod.
- Optionally enforce approvals or change tickets for large updates.
- Auditability
- Log who initiated the agent run, what file was used, and the diff applied.
- Store a snapshot of the input file and generated payload for traceability.
The agent can surface these as part of its final response: “Run ID X, initiated by Y, with Z total changes.”
Step 10: Evolve to a Reusable RDM Agent Template
Once the core design is working, you can turn it into a reusable pattern for multiple RDM domains:
- Parameterize the lookup type (
Country,Industry,ProductCategory, etc.). - Maintain domain‑specific sample prompts and mappings.
- Allow configuration of validation rules per domain (e.g., ISO code format for Country).
This lets business teams self‑serve new RDM automation patterns with minimal engineering effort: they basically get a “file‑driven RDM agent factory.”
Example User Story: Country Codes Onboarding
To tie it all together, here is a concrete example:
- A data steward downloads a country list from a CRM and adds a few missing markets.
- They log into AgentFlow and select the “Update Country RDM” agent.
- They upload the CSV and type:
“Update the Country lookup with this list. Create any missing codes and update names where changed. Do not deactivate any values.” - The agent parses the file, infers mappings, and shows a preview.
- The steward accepts and the agent calls the RDM APIs to apply updates.
- Within a minute, the lookup is updated, and the steward gets a human‑readable report plus a link to export the new full list.
No mapping configuration, no developer ticket, no custom pipelines—just an agent doing the heavy lifting.
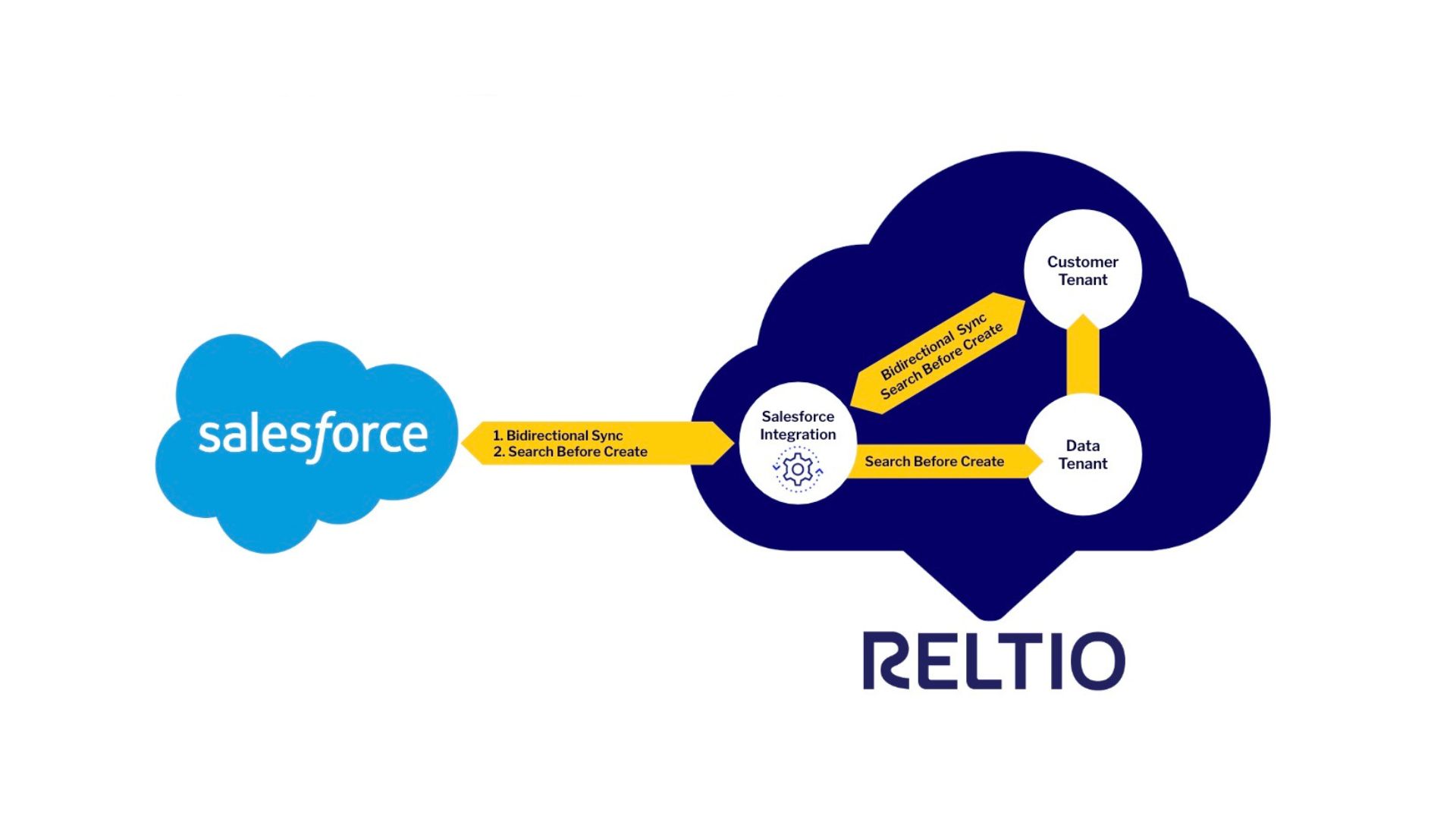
Reltio Integration for Salesforce : Search Before Create, Architecture, Configuration, and Enterprise Data Strategy

Automating Data Quality with Reltio Agentflow: A Smarter Approach to Master Data Management

From Data Mesh to Data Fabric: Choosing the Right Decentralized Architecture for Your Enterprise

Building a DataOps Culture: Accelerating Data Delivery Through Automation and Collaboration

The Data Observability Imperative: Monitoring Data Health Beyond Traditional Governance