






Introduction: The Myth of AI Failure
Artificial Intelligence is often blamed when projects fail. Models underperform, predictions go wrong, and expected ROI never materializes. From the outside, it appears to be a failure of technology.
But that assumption is fundamentally flawed.
AI doesn’t fail. Data does.
Across industries, organizations are investing aggressively in AI, yet very few are able to scale beyond pilots. A significant percentage of initiatives never reach production, and even fewer deliver consistent business value.
This is not a limitation of AI capabilities. It is a failure of data foundations.
As we move deeper into 2026, enterprises are building increasingly advanced AI systems on data that is fragmented, inconsistent, and poorly governed. And when the foundation is weak, failure is inevitable.
The AI Paradox: High Adoption, Low Impact
We are currently in what can be described as the AI paradox.
On one side, AI adoption is accelerating rapidly. Most enterprises today are experimenting with AI, and investments in GenAI and automation continue to rise. On the other side, measurable business impact remains limited. Only a small percentage of initiatives reach production, and many are abandoned after proof-of-concept.
This disconnect exists because organizations are trying to deploy intelligent systems on data ecosystems that are not designed to support them.
The Real Failure Point: Data, Not Models
When AI initiatives fail, the instinct is to question the model. Teams retrain algorithms, switch platforms, or invest in more advanced tooling.
But in most cases, the model is not the problem.
AI systems learn from data—they do not correct it. They amplify patterns, whether those patterns are accurate or flawed. This is why the principle of “garbage in, garbage out” becomes critical at scale.
If the underlying data is incomplete, inconsistent, biased, or outdated, the outputs will reflect those issues. Inaccurate predictions, biased recommendations, and unreliable decisions are not anomalies—they are expected outcomes.
The Data Failures That Kill AI Projects
Most AI failures can be traced back to a handful of recurring data issues. These challenges are often underestimated early on but become critical as systems scale.
One of the most common issues is poor data quality. Organizations frequently operate with datasets that contain missing values, duplicate records, inconsistent formats, and incorrect labels. As a result, data teams spend more time fixing data than building models, and AI outputs quickly lose credibility within the business.
Closely related is the lack of data readiness. AI-ready data is not simply data that exists—it must be structured, contextualized, governed, and accessible. Many organizations move forward with AI initiatives before preparing their data ecosystems, treating data engineering as an afterthought. This leads to stalled deployments and underperforming systems.
Data silos further compound the problem. Enterprises operate across multiple systems—CRM platforms, ERP tools, cloud warehouses—but these systems rarely integrate effectively. The result is fragmented datasets that provide only partial views of reality. AI models trained on such data produce incomplete insights, limiting their usefulness.
Another critical issue is data drift. Data evolves over time as customer behavior, market conditions, and regulations change. However, many AI systems are trained once and then left unchanged. This creates a growing misalignment between models and real-world conditions, leading to degraded performance.
In 2026, a new risk is emerging: the increasing reliance on synthetic and AI-generated data. While synthetic data can accelerate development, excessive dependence on it can lead to model collapse, where accuracy declines and outputs become repetitive or biased. Maintaining high-quality, real-world data is becoming more important than ever.
Invisible Failures: The Most Dangerous Risk
Not all AI failures are obvious. In fact, the most damaging ones are often invisible.
These failures do not appear as system crashes or major errors. Instead, they manifest as subtle inaccuracies—slightly incorrect recommendations, hidden biases, or misleading insights. Because these issues are not immediately noticeable, they often go unaddressed.
Over time, these small errors accumulate. Decision-makers begin to rely on flawed outputs, leading to poor strategic choices. Trust in AI systems gradually erodes, and organizations revert to manual processes.
The real danger is not failure—it is false confidence in incorrect outputs.
The Business Impact: Beyond Technology
AI failure is not just a technical issue—it has direct business consequences.
Financially, organizations invest heavily in AI tools, infrastructure, and talent, yet fail to generate meaningful returns. Operationally, teams spend time validating outputs instead of using them, reducing productivity. Strategically, initiatives remain stuck in pilot stages, preventing organizations from scaling innovation.
There is also a reputational dimension. Biased or incorrect AI outputs can damage brand trust, particularly in customer-facing applications.
Taken together, these impacts reveal a critical truth: poor data does not just affect systems—it affects the entire business.
The 2026 Reality: AI Is Scaling Faster Than Data
One of the defining trends of 2026 is the rapid acceleration of AI capabilities. Organizations are investing heavily in infrastructure, platforms, and automation.
However, data maturity is not keeping pace.
Many enterprises still struggle with fundamental issues such as data quality, governance, and integration. This creates a structural imbalance where AI capabilities advance faster than the data required to support them.
Until this gap is addressed, AI investments will continue to underperform.
Why Enterprises Get Data Wrong
Despite growing awareness, organizations continue to repeat the same mistakes.
Data is often treated as a byproduct rather than a strategic asset, generated as part of operations but not actively managed. At the same time, there is little accountability for data ownership, leading to fragmented responsibility across teams.
Enterprises also tend to overinvest in AI tools while neglecting foundational data infrastructure such as pipelines and governance frameworks. Finally, incentives are misaligned—teams are rewarded for launching AI initiatives, not for sustaining and scaling them.
The Shift: From AI-First to Data-First Strategy
To succeed with AI, organizations must fundamentally rethink their approach.
The traditional model—building AI first and fixing data later—has proven ineffective. A data-first strategy flips this approach by prioritizing data quality, governance, and integration before AI deployment.
This shift is not incremental. It represents a complete change in how organizations approach AI at a strategic level.
The Data-First AI Framework
To operationalize this shift, organizations need a structured approach:
1. Establish strong data foundations
This includes investing in data quality, standardization, and metadata management.
2. Implement governance by design
Clear ownership, access controls, and compliance policies must be defined early.
3. Build unified data architecture
Approaches like data fabric or data mesh help eliminate silos and create consistency.
4. Enable continuous monitoring
Data quality, drift, and anomalies must be tracked in real time.
5. Align data with business outcomes
Every dataset should be tied to a clear decision or measurable value.
The Future: Data Will Define AI Winners
As AI continues to evolve, competitive advantage will shift.
It will no longer come from better models or larger infrastructure investments. These capabilities are becoming increasingly commoditized.
Instead, success will depend on:
- The quality of data
- The strength of governance
- The level of integration across systems
Organizations that treat data as a product and invest in it strategically will be the ones that unlock real AI value.
Key Takeaway: Fix the Foundation, Not the Model
If your AI initiative is failing, the instinct may be to change the model, switch vendors, or scale infrastructure.
But the real questions are simpler:
- Is your data accurate?
- Is it complete?
- Is it unified?
- Can it be trusted?
Because in the end:
AI doesn’t fail. Data does.
Final Thought: The Real AI Maturity Curve
AI maturity is often measured by the number of models deployed or the scale of investment. But these metrics are misleading.
The true measure of AI maturity is data maturity.
Until organizations solve their data challenges, AI will remain a promise rather than a reality. But for those who get it right, AI becomes a true competitive advantage—driving better decisions, faster execution, and measurable business outcomes.

From Data Lakes to AI Lakes: The Next Evolution in Enterprise Architecture
The Hidden Cost of Bad Data in AI: A CFO’s Perspective

Why Your AI Strategy Needs a Data Product Mindset

Building RDM Update Agents with Reltio AgentFlow
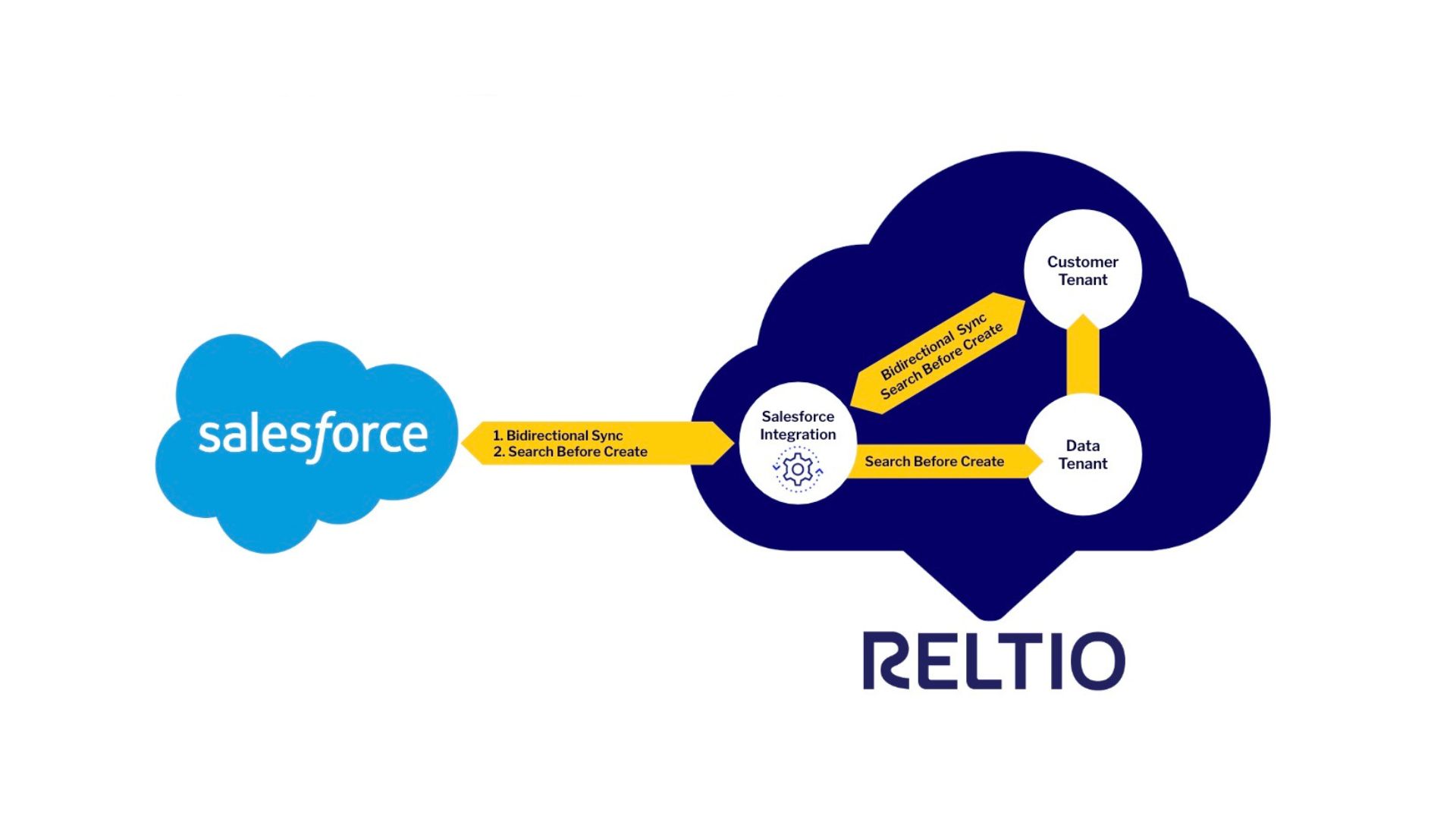
Reltio Integration for Salesforce : Search Before Create, Architecture, Configuration, and Enterprise Data Strategy