






In the rush to deploy AI agents across enterprise workflows, many organizations are captivated by the capabilities of large language models, autonomous agents, and advanced decision-making systems. The promise is compelling: AI that can streamline operations, enhance customer experiences, and uncover insights at a scale and speed unattainable for humans.
But there’s a hard truth that’s often overshadowed by the hype: your AI is only as good as the data you train it on.
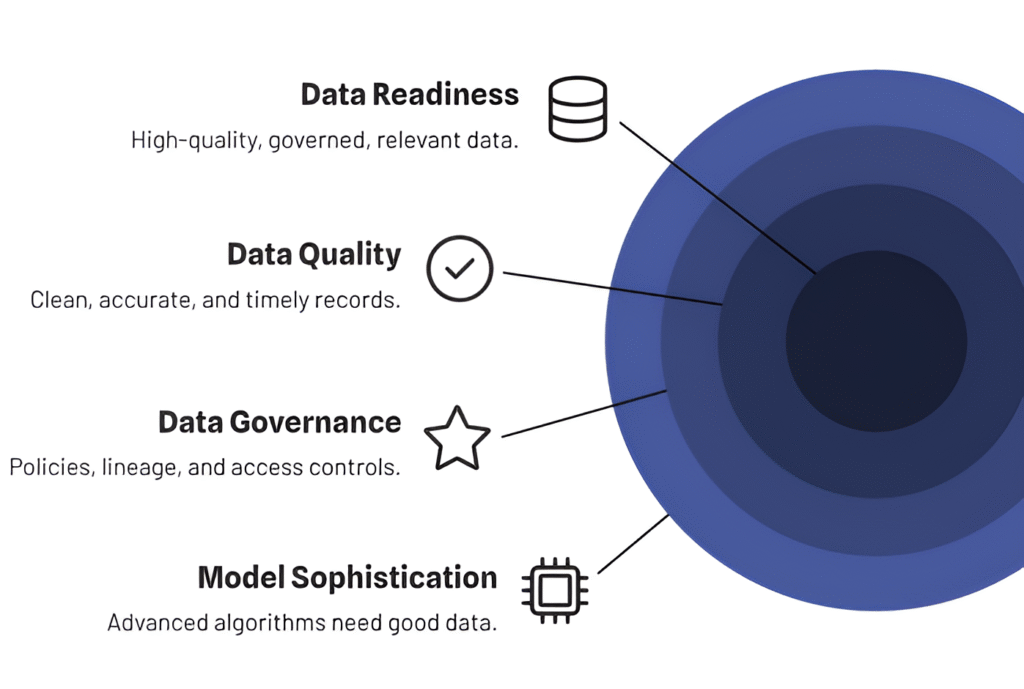
No matter how sophisticated the algorithms, if the data foundation is flawed, incomplete, biased, or outdated, your AI agents will underperform—or worse, make costly, misleading, or ethically problematic decisions.
Why Data Quality is the Bedrock of AI Agent Performance ?
Think of AI agents as incredibly intelligent apprentices. They can learn complex patterns, adapt to novel situations, and execute multi-step tasks—but they do all of this based on what they’ve seen before. If you give them high-quality, diverse, and relevant training data, they’ll learn to make accurate predictions and nuanced judgments. If you give them poor data, they’ll learn the wrong lessons.
In enterprise environments, this principle becomes even more critical because:
- Business Context is Complex: AI must understand industry-specific terminology, compliance requirements, and unique process flows.
- Decisions Carry Weight: A wrong customer recommendation in e-commerce might lose a sale; a wrong risk assessment in finance could trigger a regulatory nightmare.
- Data Volume is Vast: Enterprises deal with years (or decades) of historical records, often spread across incompatible systems and formats.
The Four Pillars of Data Excellence for Enterprise AI
To ensure AI agents perform reliably, enterprises must focus on data quality across four dimensions:
a) Accuracy
The information provided must reflect the real world. If your customer database is riddled with misspellings, outdated contact info, or mismatched IDs, your AI’s outputs will reflect that chaos.
b) Completeness
Missing data points lead to blind spots. Imagine a sales forecasting AI trained only on data from your top regions—it will struggle to predict demand in new or underserved markets.
c) Consistency
Data should be standardized across systems. If your ERP uses “USA” while your CRM uses “United States” and your marketing platform uses “U.S.,” you’ve introduced unnecessary friction into the AI’s understanding.
d) Timeliness
Outdated data is dangerous in fast-moving sectors. Training an AI agent for fraud detection on last year’s patterns might miss today’s evolving tactics.
Common Data Pitfalls That Undermine AI Agents
Even large enterprises with robust IT systems fall into avoidable traps:
- Siloed Data: When sales, customer service, and supply chain data live in separate systems, AI agents can’t see the full picture.
- Unlabeled or Poorly Labeled Data: Without clear metadata, AI struggles to differentiate between similar records or categories.
- Biased Historical Data: AI inherits historical prejudices—if a past hiring dataset overrepresents certain demographics, the AI will replicate those patterns.
- Overfitting to Internal Data: Training solely on your company’s internal records without external benchmarks can create narrow, unrepresentative models.
Strategies to Build a Data Foundation for AI Success
Enterprises that succeed with AI agents treat data governance as a strategic imperative, not an afterthought. Here’s how:
1. Establish Enterprise-Wide Data Governance
Define clear ownership, policies, and quality controls. Data stewards and governance boards should ensure standards are enforced.
2. Invest in Data Cleaning and Enrichment
Before training an AI agent, run comprehensive data audits to remove duplicates, fill gaps, and validate accuracy. External data enrichment can bring fresh insights.
3. Enable Data Integration
Use data lakes, warehouses, or mesh architectures to break down silos. Your AI should be able to cross-reference customer sentiment, transaction history, and operational metrics seamlessly.
4. Monitor Data Drift
Even well-trained models degrade if the underlying data distribution changes (e.g., consumer behavior shifts after a major economic event). Set up ongoing monitoring and retraining cycles.
5. Prioritize Ethical and Representative Data
Proactively remove bias where possible, and ensure datasets reflect diverse perspectives and use cases.
Real-World Example: When Data Breaks the AI
A global retailer launched a customer service AI agent to handle live chat inquiries.
The training data came from historic chat logs—seemingly a goldmine of real interactions. But here’s the issue:
- The logs skewed heavily toward English-speaking customers from urban areas.
- Product descriptions were inconsistent between the CRM and website database.
- Many transcripts contained outdated return policies.
The AI agent confidently gave incorrect return instructions to customers in rural markets, creating friction, refunds, and brand damage.
The fix? A coordinated data overhaul—centralizing product information, updating policies in training data, and adding multilingual support—dramatically improved agent accuracy and customer satisfaction.
The Bottom Line
Enterprises often think model sophistication is the winning factor in AI success. In reality, the differentiator is data readiness.
Without high-quality, relevant, and well-governed data, even the most advanced AI agents are like top-tier athletes running on an empty stomach—they simply can’t perform at their potential.
As the saying goes in AI:
Garbage in, garbage out.
But in the enterprise, it’s not just garbage—it’s missed revenue, damaged reputation, and lost competitive edge.
Your AI agents will only ever be as good as the data you give them.
Treat your data like the strategic asset it is, and your AI will reward you in kind.

Why 2025 Is the Breakout Year for AI-Driven Transformation in Manufacturing

Enterprise Data Architecture for the Age of AI Agents

Data Governance: The Critical Gap in Every GenAI Strategy.

AI-Powered Automation and Workflow Optimization: The Next Frontier for Enterprise Transformation

Strategic AI Business Integration and Outcome Measurement